Bonus: practice your algorithmic-fu¶
This exercise is "for fun". Don't feel obliged to do it! For this exercise you can use the standard library only (maybe with numpy if you want to). Let's download some data:
from urllib.request import Request, urlopen
import json
# Parse the given url
url = 'https://raw.githubusercontent.com/fmaussion/scientific_programming/master/data/rgi_intersects.json'
req = urlopen(Request(url)).read()
# Read the data
data = json.loads(req.decode('utf-8'))
This dictionary contains two lists of N glacier identifiers. Each list contain one element of the pairs of glaciers in Iceland which have a connection (an ice divide) with each other. In other words, data['RGIId_1'][i] shares a connection with data['RGIId_2'][i], for i in range(len('RGIId_1')). Here is a map to help you visualize things a little better:
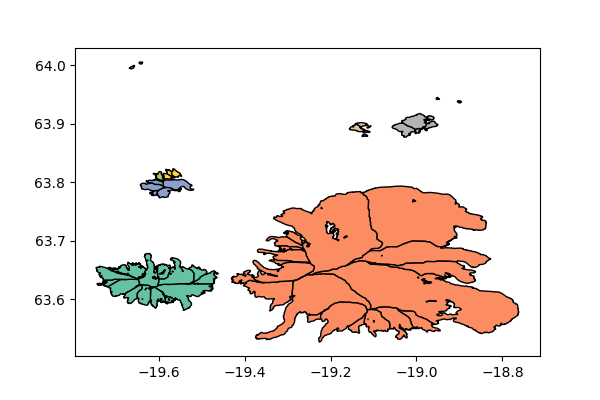
The colors mark the clusters, there are 7 in total (the individual glaciers do not count).
The goal of this exercise is to find these seven clusters and list the glaciers belonging to each other.
As a warm up, you should start with a smaller example. Given the following pairs:
(A, B)
(A, C)
(C, D)
(E, F)
I'm asking to find the two clusters:
(A, B, C, D)
(E, F)Back to the table of contents